先要从 InnoDB 的索引实现说起,InnoDB 有两大类索引:
- 聚集索引 (clustered index)
- 普通索引 (secondary index)
InnoDB 聚集索引和普通索引有什么差异?
InnoDB 普通索引的叶子节点存储主键值。
注意:只有 InnoDB 普通索引才存储主键值,MyISAM 的二级索引都是直接指向数据块的。
InnoDB 聚集索引 的叶子节点存储行记录,因此,InnoDB 必须要有,且只有一个聚集索引:
- 如果表定义了主键,则主键就是聚集索引;
- 如果表没有定义主键,则第一个 not null 的 unique 列是聚集索引;
- 否则,InnoDB 会创建一个隐藏的 row-id 作为聚集索引;
注意:所以主键查询非常快,直接定位行记录。
举个例子,简单设置一张表,设置几条数据进去:
1 |
|
- id 为主键,聚集索引,叶子节点存储行记录;
- name 为索引,普通索引,叶子节点存储主键值,即 id;
两个 B+ 树索引分别如图:
通常情况下,需要扫码两遍索引树。例如:
1 | SELECT * FROM t WHERE name = 'lisi'; |
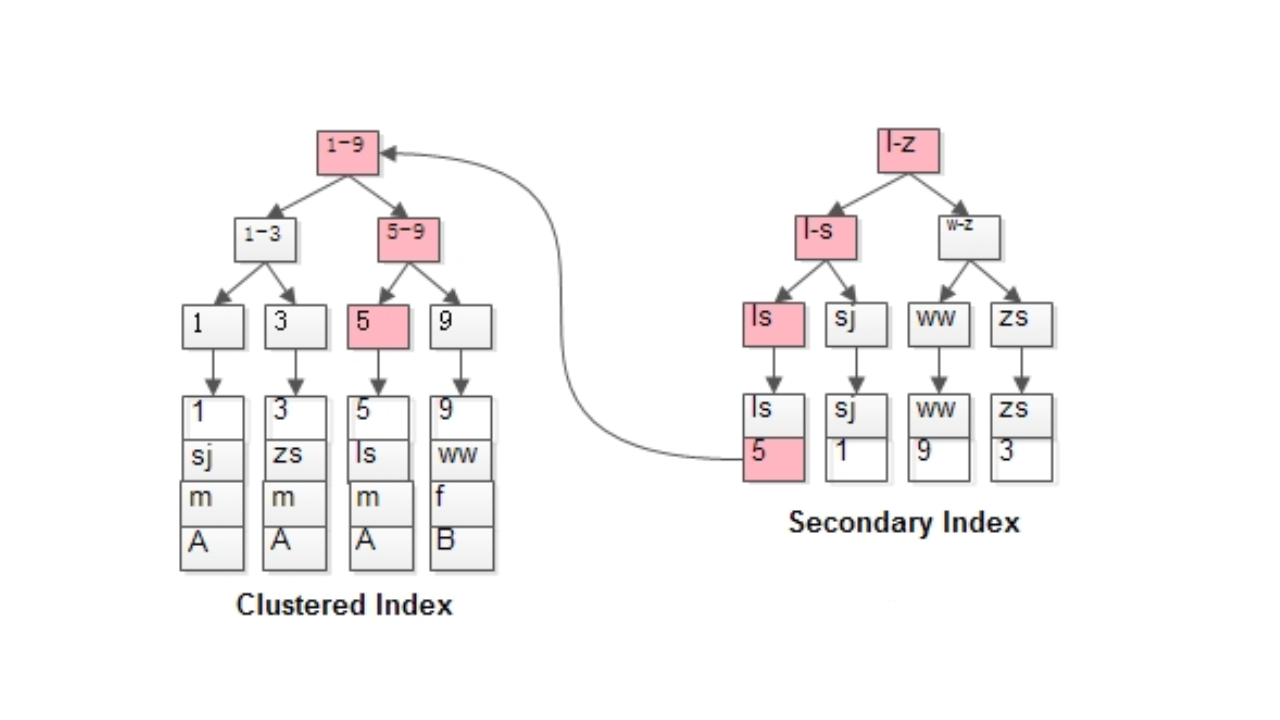
如粉红色路径,需要扫码两遍索引树:
- 先通过普通索引定位到主键值 id=5;
- 再通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。
我们知道 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次,这样就会比较慢。覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去(或者说 查询的字段都已经建立了索引)。还是用上边的例子 user 表,我们用 EXPLAIN 关键词分析来看下结果。
第一个SQL语句:
1 | EXPLAIN SELECT id, name FROM user WHERE name='shenjian'; |
 能够命中 name 索引,索引叶子节点存储了主键 id,通过 name 的索引树即可获取 id 和 name,无需回表,符合索引覆盖,效率较高。
能够命中 name 索引,索引叶子节点存储了主键 id,通过 name 的索引树即可获取 id 和 name,无需回表,符合索引覆盖,效率较高。
第二个SQL语句:
1 | EXPLAIN SELECT id, name, sex FROM user WHERE name='shenjian'; |

能够命中 name 索引,索引叶子节点存储了主键 id,但 sex 字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过 id 值扫码聚集索引获取 sex 字段,效率会降低。
如果把 (name) 单列索引升级为联合索引 (name, sex) 就不同了:
1 | ALTER TABLE `user` |

再次执行,第二个SQL语句:
1 | EXPLAIN SELECT id, name, sex FROM user WHERE name='shenjian'; |
 能够命中联合索引,索引叶子节点存储了主键 id,通过联合索引的索引树即可获取`name` 和 `sex`,无需回表,符合索引覆盖,效率较高。
能够命中联合索引,索引叶子节点存储了主键 id,通过联合索引的索引树即可获取`name` 和 `sex`,无需回表,符合索引覆盖,效率较高。
MySQL 回表优化
场景举例:如果按照下边的写法(普遍大家公认写法),当页数达到一个比较大的量级后,可能会变得非常卡。
1 | SELECT o1.* FROM orders WHERE sn='XD12345678' LIMIT 10000,10 |
因为数据表是 InnoDB,根据 InnoDB 索引的结构,查询过程为:
通过二级索引查到主键值(找出所有 sn=’XD12345678’ 的 id)。
再根据查到的主键值通过主键索引找到相应的数据块(根据 id 找出对应的数据块内容)。
根据 offset 的值,查询 10010 次主键索引的数据,最后将之前的 10000 条丢弃,取出最后 10 条。
因为我们要查询 o1.*,前边丢弃的 10000 条数据,经过大量回表操作,造成了大量的 I/O 消耗,浪费了很多性能,导致查询时间变得很长。
1 | SELECT o1.* FROM orders o1 |
而这样的写法在 o2 分页查询时根本无需回表只查询 id,最后再做一个内连接根据主键取出数据,虽然增加了 SQL 语句的复杂度,但是性能非常好。
关注获取更多资源
